
瀏覽各大網站、登入與註冊時,相信大家一定都有遇到要「機器人驗證」的時候吧?
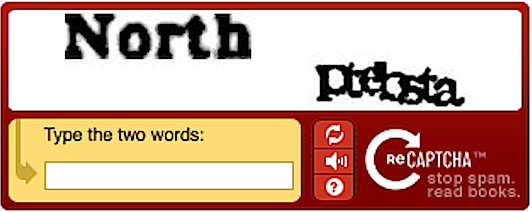
從最早期經常讓人類也看不懂的「輸入圖中的英數字」、到「點選有OO的照片」,以至於如今最常見的「我不是機器人」,這樣的驗證充斥在許多大大小小的網站中…

這些驗證用久了,不知道大家是否有想過一個問題,輸入英數字、點選照片來辨認是否為真人還算好理解,但是「我不是機器人」只是單純打個勾,網站為什麼就知道你真的「不是機器人」了呢?日本的科技業人力網站「PERSOL TECHNOLOGY STAFF」就發布了一篇文章,文章內容中訪談了橫濱「情報安全研究所」的資工教授大久保隆夫,為大家解惑。

大久保教授開宗明義表示,網站或多或少都會遇到惡 意程式,利用大量註冊、重複登入等方式來造成網站癱 瘓;因此「CPATCHA」就是用來辨認人類與機器人的系統,大家常見的「我不是機器人」則是Google提供的辨認服務「reCPATCHA」。
這種「reCPATCHA」還有很多型態,只要是從過去就常用網路的人也一定不陌生,最早期就是一些歪七扭八的英數字,到後來的選擇圖片等,都是屬於Google提供的「reCPATCHA」;而「reCPATCHA」的辨認能力進化到如今,則成了「我不是機器人」。
所以這個「我不是機器人」到底是怎麼運作的呢?
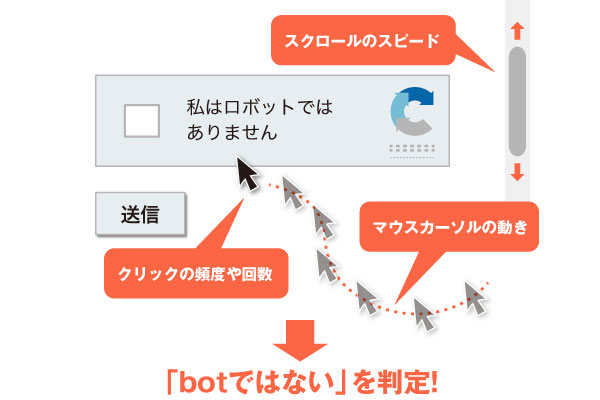
原來「reCPATCHA」並不是在你點選打勾那瞬間判斷,而是在你進入網站的那一刻起,就一直在記錄你的IP位址、滑鼠移動軌跡、捲軸滾動方式等;而在你點選「我不是機器人」的時候,這些資料就會上傳到資料庫中,藉此來辨別你到底真正的人類,還是來搗亂的惡意程式。
當然,有時候資料庫還是會有辨別不出你到底是真的人類還是機器人的時候,那麼點選下去之後就會跳出「選取帶有OO的圖片」機制,進行雙重驗證。

大久保教授也提到,之所以「reCPATCHA」會有從最早「輸入英數字」到如今「我不是機器人」的演變,是因為不只Google的資料庫在進步,惡意程式的AI系統也越來越先進,當初的「輸入英數字」甚至會有機器人可以高準確率辨認,一般人類卻反而讀不懂的情形發生。

因此大久保教授推測,雖然短期間內「我不是機器人」還是主要的辨認方式,但隨著惡 意程式開發的AI越來越厲害、資料庫越來越齊全,在不遠的未來「我不是機器人」也很有可能走入歷史,改由另一種全新的、機器模仿不來的驗證方式來進行。
大久保教授最後結論表示,每當做出一個新的安全系統,很快就又會有人透過各種方式來繞過這個系統,資工安全的相關開發,就是這樣子不斷地你來我往之間而演變的。
延伸閱讀
【五奇不有】這些生物曾經居住在地球上?!五種遠古巨大物為什麼消失… │熊熊想知道
(37)